

Why Omnisearch Went from Python to C++

Patricia Butina
Marketing Specialist
Published:
August 12, 2025
Topic:
Deep Dive

Every great startup story begins with overcoming challenges, but Omnisearch stands out for facing an extraordinary hurdle: they had to build their foundation not once, but twice. Matej Ferencevic, Omnisearch’s CTO, shared his reflection on this journey:
“I remember our first 'duct-tape' prototype, a modest multimedia search engine we cobbled together in pure Python. This early version supported basic keyword searches through transcripts and metadata. It was taking about two seconds per query and it maxed out at only a few thousand entries before starting to struggle. But at that stage, that was enough. This humble engine powered our first demos, secured our initial 30 paying customers, and even won us our first big enterprise partner. Python allowed us to rapidly prove that there was genuine demand for powerful multimedia search, giving us the confidence to dream even bigger.”
In this blog, we’ll explore Omnisearch's bold transition from Python to C++, and how that leap transformed a modest prototype into an enterprise-grade platform.
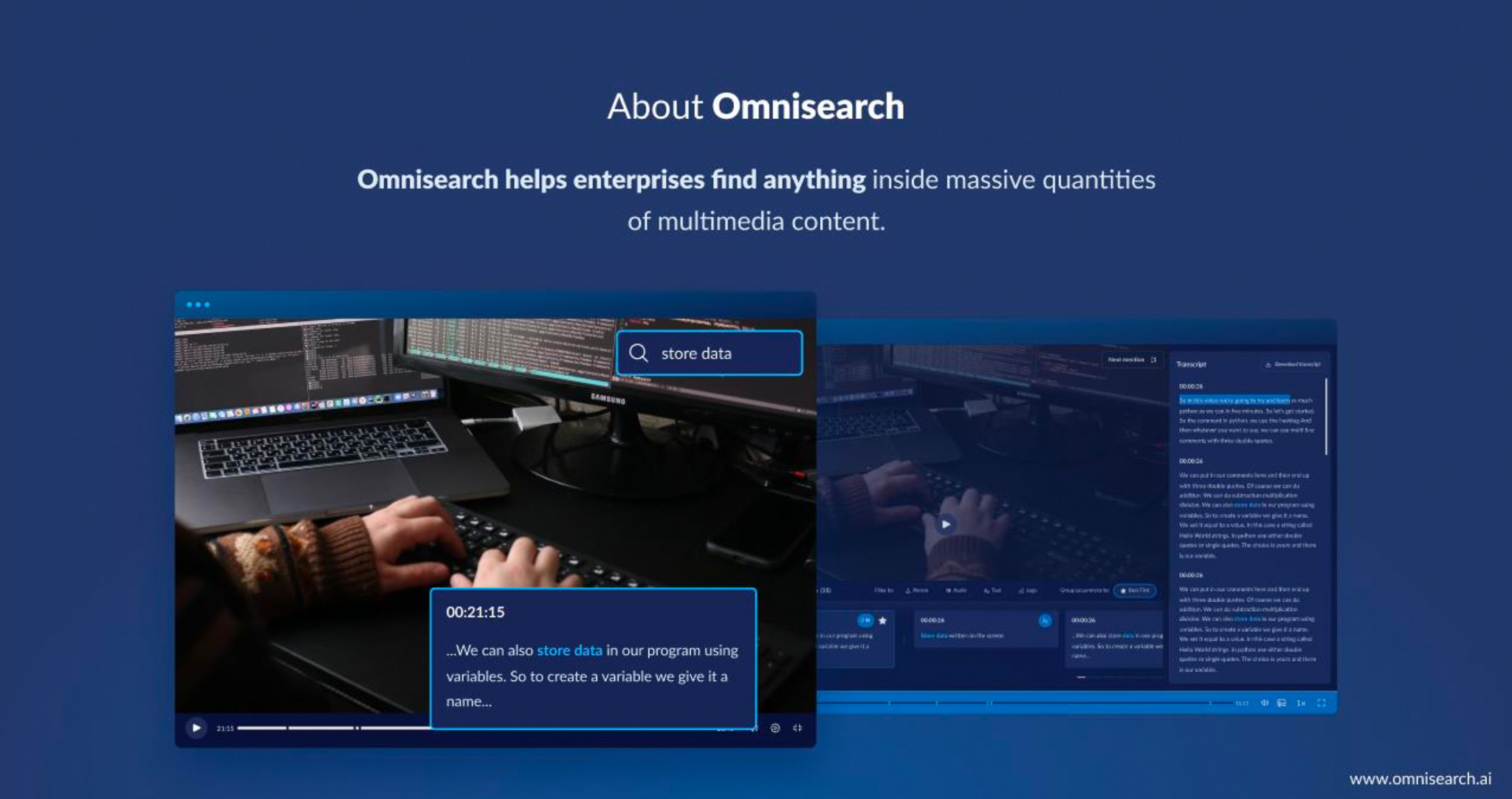
Why We Migrated from Python to C++
Omnisearch’s story begins like many startups – with a quick Python MVP. Python is beloved for its simplicity and rapid development, which helped us get an initial product out the door and even land our first customers. But as our user demands grew, Python’s limitations became painfully obvious. The original search engine (Omnisearch v1) delivered “satisfactory” query times of around 2 seconds per query on small datasets (~2,000 entries). This was acceptable for demos, but not for the snappy experience we envisioned. Moreover, that Python-based solution struggled to scale beyond a few thousand indexed items and offered only basic exact-match keyword search. We had pushed Python to its limits by squeezing out minor speed-ups (e.g. using lookup tables in PostgreSQL), but it wasn’t enough.

The decision was clear: to serve larger clients and more complex queries, we needed a fundamental overhaul. We chose C++ as the new backbone of our engine. Why C++? Because it’s the “immortal” systems language that excels at exactly what Python struggled with: performance and control. By rewriting the core in C++ (while keeping some high-level “glue” logic in Python for convenience), we unlocked an engine that now handles 50+ million indexed entries (including over 50k hours of video content) with advanced semantic search – all with sub-200ms query times. In short, we traded Python’s ease-of-use for C++’s raw power, and it completely changed the game. As Matej put it during the talk, this upgrade “allowed us to acquire several enterprise customers each larger than all of our first 50 customers combined”. When your technology can scale that much further, business growth tends to follow.

Python vs C++ in Real Life
We’re big fans of Python, but it’s always fun (and useful) to revisit how things actually perform under the hood. Let’s warm up by looking at two Python snippets that, on the surface, do the exact same thing but whose performance tells a very different story.
data = "hello" * 10_000_000
count = 0
for c in data:
if c == "1":
count += 1
print (count)Time complexity: O(n) — We’re iterating through every character in the string.
Runtime measurement:
$ time python3 example1.py
real 0m2.759s
user 0m2.746s
sys 0m0.012s
Roughly 2.75 seco'nds. That’s not terrible given the string length (50 million characters), but there’s clearly room for improvement. Now let's look at another, slightly different example, where we're leveraging built-in str.count:
data = "hello" * 10_000_000
print(data.count("1"))Time complexity: Still O(n) — in theory. But here’s the trick: str.count isn’t implemented in Python; it’s implemented in optimized C inside CPython.
Runtime measurement:
$ time python3 example2.py
20000000
real 0m0.109s
user 0m0.098s
sys 0m0.012s
That’s over 25× faster, even though Big-O says both are O(n) operations.
Example 2 is "cheating" in the best possible way: instead of interpreting Python bytecode for every loop iteration, it hands the problem to a low-level, highly optimized C routine that does all the work in one go.
This highlights an important reality: Big-O notation tells you how runtime scales, but not the constant factors and in Python, those constants can be massive because of interpreter overhead. If you can replace a Python loop with a built-in function backed by C, you’ll often see performance leaps like this.
#include <cstdint>
#include <iostream>
#include <string>
#include <string_view>
int main() {
std::string_view hello("hello");
const uint64_t kNumberOfCopies = 10'000'000;
std::string data;
data.reserve(hello.size() * kNumberOfCopies);
for (uint64_t i = 0; i < kNumberOfCopies; ++i) {
data.append(hello);
}
uint64_t count = 0;
for (const auto &c : data) {
if (c == '1') ++count;
}
std::count << count << std::endl;
return 0;
}
~/omnisearch$ clang++ -02 -DNDEBUG
-std=c++20 -o example3 example3.cpp &&
time ./example3
20000000
real 0.0.055s. 50x and 2x faster
user 0m0.051s
sys 0m0.004s// Previous includes
#include <immintrin.h>
#include <xmmintrin.h>
int main () {
// Initialize 'data'.
uint64_t count = 0;
uint64_t position = 0;
while (position + 16 <= data.size()) {
auto cs = _mm_loadu_si128(
reinterpret_cast<const __m128i *>(&data[position]));
auto cmp = _mm_cmpeq_epi8(cs, _mm_set1_epi8('1'));
auto mask = _mm_movemask_epi8(cmp);
count += __builtin_popcount(mask);
position += 16;
}
while (position < data.size()) {
int c = data[position];
if (c== '1') ++count;
++position;
}
std::cout << count << std::endl;
return 0;
}~/omnisearch$ clang++ -02 -DNDEBUG
-std=c++20 -o example4 example4.cpp &&
time ./example4
2000000
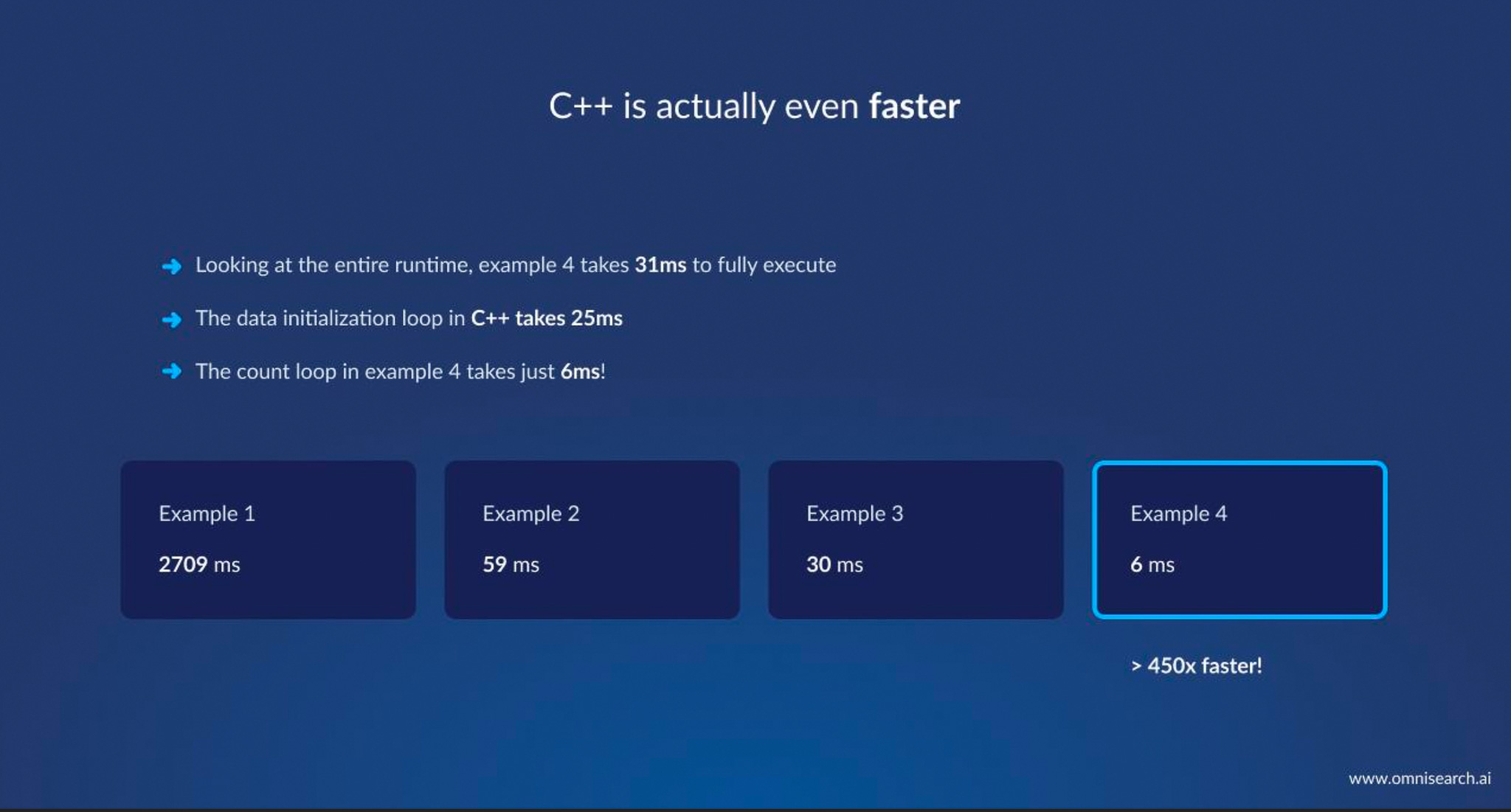
real 0m0.031s 89x, 3.5x and 1.8x faster
user 0m0.027s
sys 0m0.004sOf course, rewriting code in C++ isn’t a magic wand; it demands careful engineering. But it gave us two huge advantages: freedom from Python’s limitations, and the ability to do deep low-level tuning. Freed from the global interpreter lock, our C++ engine can comfortably utilize multiple cores and threads. Freed from Python’s high-level abstractions, we can choose optimal data structures and memory layouts. The outcome is that queries which used to take a couple of seconds in Python now complete in a few hundred milliseconds in C++ – easily 10×+ faster at the high level. And as the earlier micro-benchmark showed, for certain inner loops the speedup can be hundreds of times if we really push the pedal to the metal.
Architecting for Speed: C++ to the Rescue
Moving to C++ didn’t just mean rewriting Python code line-by-line. We took the opportunity to redesign the architecture of our search engine for maximum speed. One big change was how we handle data in memory. In Python, we had been somewhat constrained, often leaning on external systems (like a SQL database with look-up tables) to accelerate searches.
With C++, we brought much of the data handling in-house, in memory, structured in ways that are efficient for our access patterns. We adopted native data structures (like std::vector and custom indices) that gave us contiguous memory layouts and predictable performance. We also split responsibilities: Python now serves mainly as an orchestration and integration layer (handling API requests, glue logic, etc.), while C++ does the heavy lifting of query processing, text/audio indexing, and algorithmic searching. This hybrid approach lets us keep the productivity of Python for high-level tasks without sacrificing the performance of C++ where it matters most – a “best of both worlds” strategy.
How we reduced our memory usage by 80%?
struct MemoryHog {
const void *ptr;
uint64_t first;
uint64_t second;
uint64_t third;
};
std::vector<std::vector<MemoryHog>> many_many_memory_hogs;This code snippet illustrates a classic case of hidden memory bloat in C++ due to data structure choices and layout. Here, MemoryHog is a small struct with a pointer and three uint64_t values, which might seem lightweight at first glance. However, because of alignment requirements, the compiler will pad the struct to a multiple of its largest member’s alignment — in this case 8 bytes — meaning each MemoryHog consumes more memory than the raw sum of its fields. The real kicker is in the std::vector<std::vector<MemoryHog>>: each nested vector has its own dynamic allocations, capacity slack, and allocator metadata, multiplying the overhead dramatically when storing millions of these objects. This can easily lead to multi-gigabyte footprints where only a fraction is actual payload. The “80% reduction” likely came from flattening the structure (using a single contiguous std::vector<MemoryHog> or even splitting fields into separate arrays for better cache locality) and removing the double-vector indirection, turning a memory hog into something far leaner and faster to traverse.
Crucially, C++ opened the door to system-level optimizations that were impossible before. We fine-tuned compiler settings and build flags to squeeze out every drop of speed (enabling high optimization levels like -O2/-O3, link-time optimization, etc.). We also began utilizing CPU-specific instructions – which brings us to some of the low-level magic that made that 450× speedup possible. A great example is SIMD vectorization: by using SSE/AVX intrinsics, we let one CPU instruction operate on multiple pieces of data in parallel. In the Python world, processing elements one-by-one was the norm; in C++, we could crunch 16 or 32 bytes at a time with a single vectorized instruction.
In Matej’s talk, the C++ code that achieved the final 6 ms runtime used intrinsics from <immintrin.h> (SSE/AVX) to check 16 characters in a string simultaneously. This kind of data-parallel approach is something modern CPUs excel at, but it requires a language like C/C++ (or lower-level libraries) to utilize. By writing a bit of extra C++ code – instructing the CPU to load 128-bit chunks and compare them in one go – we tripled the speed of that loop (going from ~30 ms to ~6 ms). Had we stuck with Python, such an optimization would be out of reach without rewriting critical sections in C anyway. In summary, migrating to C++ allowed us to architect for speed: from high-level design (in-memory indexes, multithreading) down to low-level instructions (SSE/AVX), we finally had full control over performance tuning.
How We Achieved 450× Speedups
Let’s geek out a bit more on the low-level techniques that yielded those massive speedups. The C++ rewrite was not a one-and-done deal – it was followed by numerous profiling and optimization cycles. Here are a few of the key optimizations we implemented:
- Loop Unrolling and SIMD: Wherever possible, we unrolled tight loops and employed SIMD instructions to process data in parallel chunks. For example, to count occurrences of a character, we loaded 16 bytes at once into a 128-bit SSE register and did a vectorized compare, instead of checking one byte at a time. This change alone gave a huge constant-factor speed boost. (We could even use AVX2/AVX-512 with 256-bit or 512-bit registers for certain tasks, doubling or quadrupling the data processed per instruction – though with diminishing returns due to memory bandwidth constraints.) The net effect is that the CPU does more work per tick, which is how a 450× gap becomes possible when comparing to Python’s item-by-item processing.

- Efficient Memory Access Patterns: We reorganized data to be cache-friendly. C++ lets you arrange structures in memory contiguously, so we made sure frequently accessed data (like the search index entries) sit next to each other in arrays (
std::vector), improving spatial locality. This reduces cache misses dramatically. In contrast, Python’s use of pointers and objects can scatter data around the heap, which hurts cache utilization. By keeping our hot data in contiguous blocks, we let the CPU cache do its job, feeding the processor with data at high speed. This change is harder to quantify in a single number, but it was instrumental in achieving the consistent sub-200ms query times for large datasets.

- Concurrency and Parallelism: While the single-threaded speedups were already impressive, we also leveraged multithreading in C++ for tasks like indexing and query execution when possible. The absence of Python’s Global Interpreter Lock (GIL) meant we could actually execute threads truly in parallel. For example, splitting a search query across multiple CPU cores (each core searching a portion of the index) can linearly cut down query latency. This wasn’t feasible in the Python version. Now, not every query or operation parallelizes neatly, but when they did, we took advantage. The result is an engine that scales with modern multi-core servers, whereas the old Python engine was largely stuck on a single core.
It’s worth emphasizing that none of these tricks are “premature optimizations” – they were guided by profiling and a deep understanding of our workload. We didn’t rewrite everything in hand-tuned assembly (that would be overkill and unsustainable). Instead, we identified the bottlenecks and attacked them with the appropriate low-level optimization. Python made that nearly impossible, whereas C++ made it fun (in a masochistic sort of way). It’s a reminder that with C++, you can operate on a spectrum from high-level (clean abstractions, OO design) down to bare metal (bit fiddling, intrinsics) within one codebase. That is incredibly powerful for engineering excellence.
Memory Matters: Cutting Footprint by 80%
Speed was only half the battle – we also faced a growing problem with memory usage. Our search engine deals with a lot of data: think indexes of words, timestamps in videos, pointers to content, etc. In the initial C++ version, we represented a lot of this data in straightforward ways (basically, in large arrays of structs). It worked and was fast, but as we scaled up the indexed content, the memory footprint ballooned to unwieldy levels. In fact, early on our C++ engine consumed about 4510 MiB (4.5 GB) of memory for a certain large dataset. We wanted to bring that way down – both to lower our infrastructure costs and to ensure the engine could run comfortably even in memory-constrained environments.

To attack this, we embarked on what we call our Memory Diet – a series of low-level optimizations to compress and compact our in-memory data structures. By the end, we slashed memory use by roughly 76% (bringing that 4510 MiB down to about 1073 MiB). Here’s how we did it:
- Understanding the Data: First, we analyzed the characteristics of the data we were storing. We noticed a few important things: (1) once stored, the data isn’t modified often (mostly append-only indices), (2) read performance is far more critical than write performance for our use case, and (3) many numeric values we stored were relatively sequential and sorted. For instance, a lot of our data were 64-bit integers (IDs, offsets, etc.), but not all 64 bits were actually utilized – many values were small or incrementally increasing. This analysis hinted that we were wasting space by naively using 64-bit fields for everything
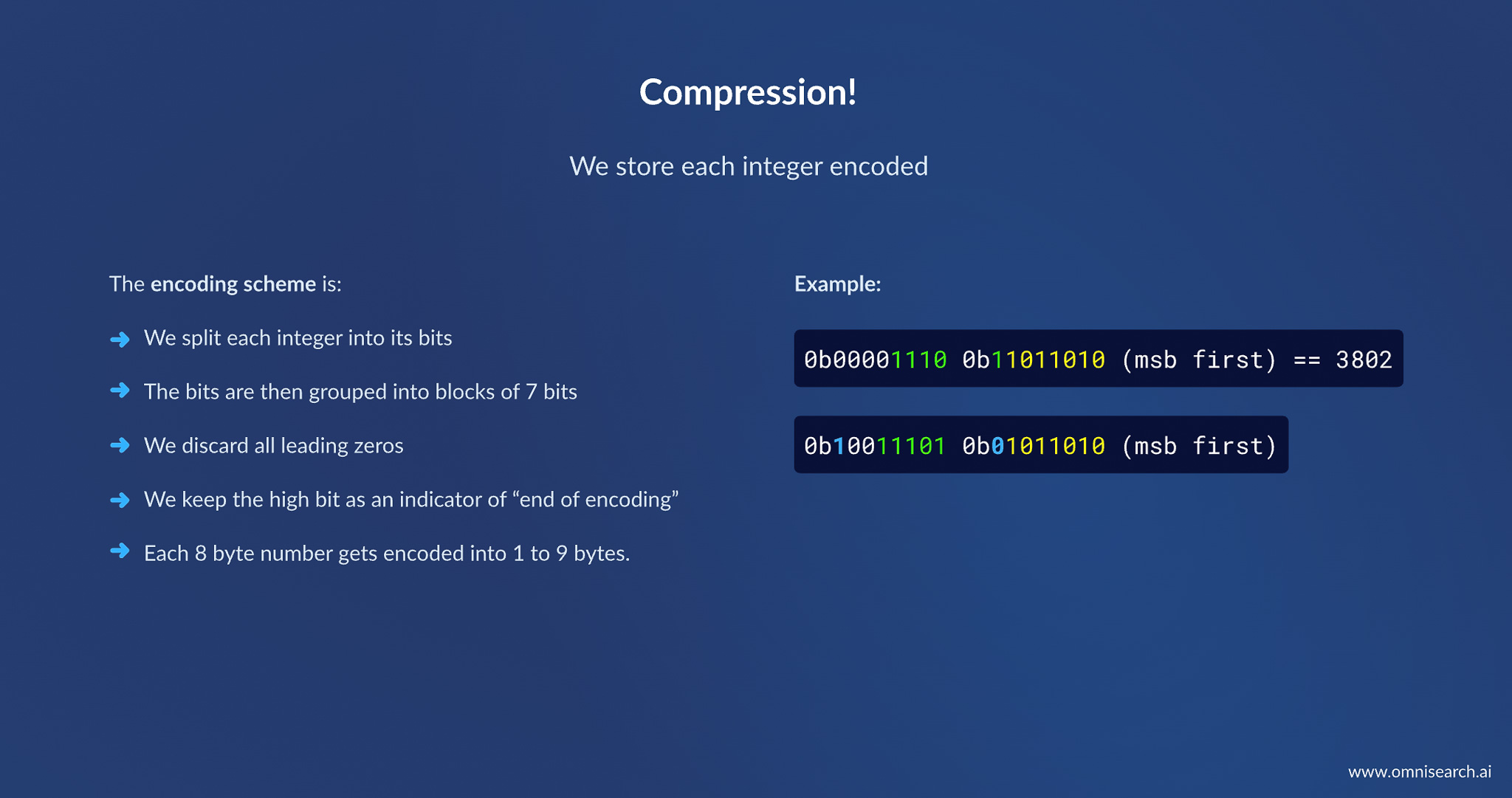
- Variable-Length Integer Encoding: We implemented a custom compression scheme for those 64-bit integers to take advantage of their typically small magnitude. Essentially, we applied a form of variable-length encoding(similar to how Google’s Protobuf or varint works). As described in the lecture slides, we split each integer’s binary representation into 7-bit chunks, discard leading zeros, and use the high bit of each byte as a continuation flag. In practice, this means a number that might normally take 8 bytes (64 bits) could be stored in 1–5 bytes on average (and at most 9 bytes in the worst case) depending on its value. Most of our typical values (which required ≤10 bits or ≤24 bits, etc.) collapsed down to 2 or 3 bytes instead of 8. We applied this compression to every large integer field in our data structures. The space savings were immediate and significant.
- Pointer Compression: Our data structures contained a lot of pointers (for example, pointing to text transcripts or video metadata in memory). On a 64-bit system, each pointer is 8 bytes. But we realized many of those bits were always zero due to alignment and how virtual addressing works. In fact, on x86-64, only 48 bits of an address are actually used by hardware; and if an object is 8-byte aligned, the lower 3 bits are always zero. So we took a page from the Linux kernel’s playbook: we encoded pointers more compactly. We shifted every pointer right by 3 (essentially dividing by 8) to drop those always-zero bits, and then treated the remaining 45 bits as an integer that we compress with the same variable-length scheme described above. In practice this shrank pointer fields from 8 bytes to around ~4 bytes on average. When you have millions of pointers, halving their size is a big win.
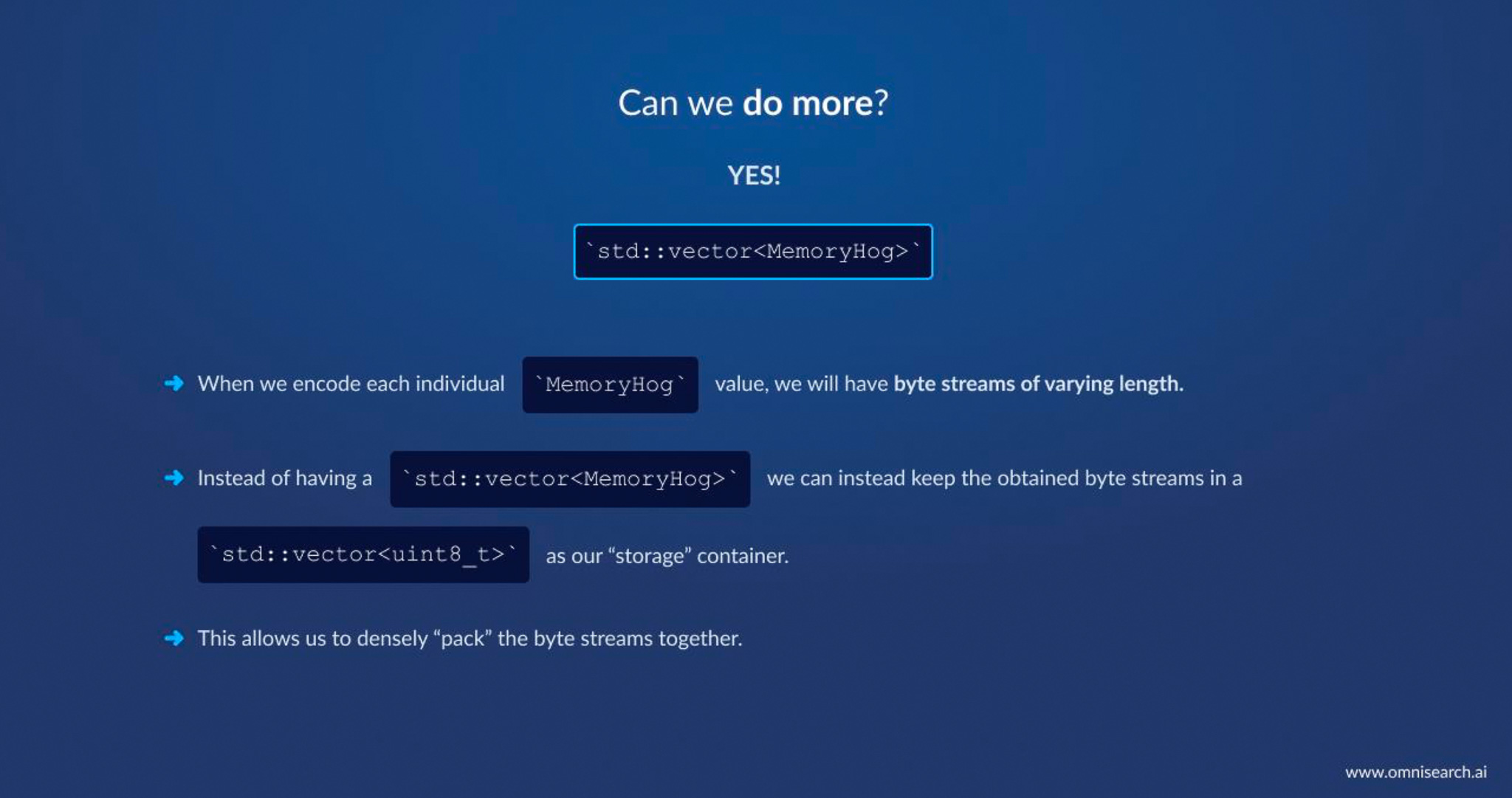
- Dense Packing of Structures: Initially, we stored records as an array of structs (each struct holding a pointer and three integers, among other things). This was convenient but not memory-optimal – each
MemoryHogstruct had some padding/alignment overhead, and each was of fixed maximum size. After compressing the integers and pointers, their lengths varied per record. So we changed strategy: instead of keeping an array of structs, we kept arrays of bytes and packed each compressed record contiguously with no wasted space. Think of it like turning a fixed-size table into a tightly packed byte stream. We still keep an index to know where each record’s data starts, but the data itself is squashed together. This eliminated the padding and any unused bits within each record.
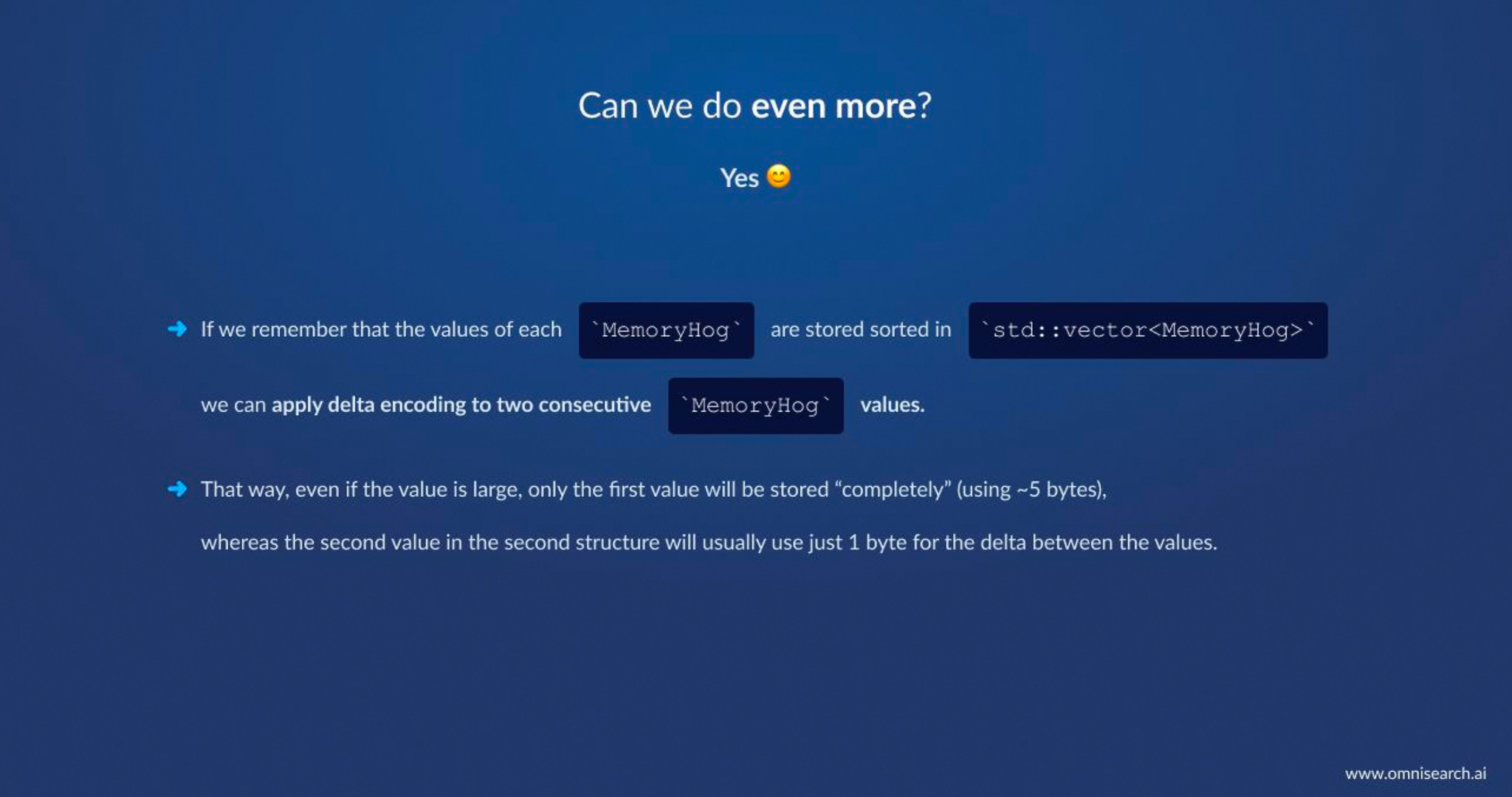
- Delta Encoding of Sequential Data: We didn’t stop at compressing individual values – we also looked at relationships between records. Recall that many records were stored in sorted order by certain fields (say an increasing timestamp or ID). For such sequences, we applied delta encoding: instead of storing each value in full, we store the first value normally, and then store the differences between consecutive values. If record B’s value is only, say, +5 relative to record A’s value, that delta (5) might only take 1 byte to encode, even if the absolute values were large. In our implementation, this meant if you have two consecutive
MemoryHogentries in a vector, their fields are very close, so the second one is stored as small deltas from the first. Thus, even when an occasional value in our data is large, all the following nearby values will often be small deltas. This final trick further squeezed out bytes from the storage without sacrificing query speed (we can decode deltas on the fly very fast).
By combining all these techniques, the memory savings were enormous. After the “diet,” our index structure that was ~4.5 GB shrank to ~1.07 GB. That’s roughly a 76% reduction in memory footprint. And as a bonus, making the data so compact actually improved speed as well – the same process ran about 27% faster end-to-end, likely because the CPU has less data to move around and more of it fits in cache. This is a great example of a virtuous cycle: optimizing for memory helped performance, which in turn helps us scale to even larger workloads on the same hardware.
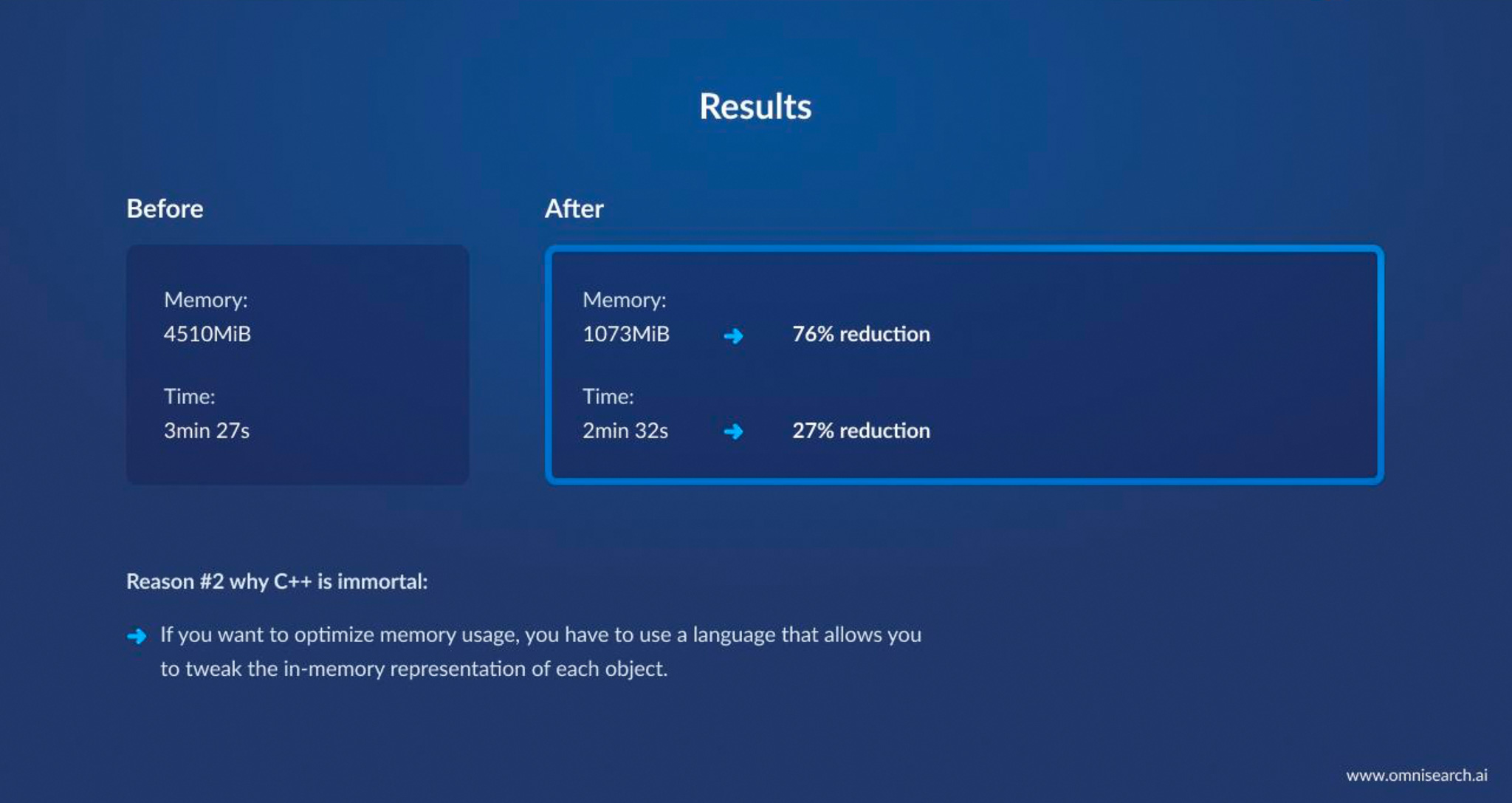
Finally, an important takeaway here is that these kinds of deep memory optimizations are only possible in a systems language like C++. As one slide neatly summarized, “If you want to optimize memory usage, you have to use a language that allows you to tweak the in-memory representation of each object.” In a higher-level environment (Python, Java, etc.), we simply could not have achieved this level of control over bytes and pointers. This was “Reason #2 why C++ is immortal,” as Matej quipped – the ability to squeeze every bit (literally) out of your data structures is a superpower when you need it.
Scaling Up and Serving Enterprise Clients
The shift from Python to C++ and the subsequent optimizations did more than make things faster and lighter on paper – it fundamentally transformed what our product could do. With Python, we were constrained to small-scale deployments; with C++, we welcomed Big Data with open arms. After the migration, Omnisearch’s engine could index hundreds-to-thousands of times more data while delivering sub-second query responses. To put it concretely, we went from supporting <2k documents to >50 million documents (plus tens of thousands of hours of audio/video content) without degrading search speed. This unlocked use cases for enterprise clients who might have terabytes of content – something utterly unthinkable with our original architecture.
For our customers, these improvements mean they can plug in enormous knowledge bases, media libraries, or archives into Omnisearch and get instant, relevant results. There’s no more “go get a coffee while it searches” – it’s now “results appear before you can blink.” The reliability improved too: the tighter memory usage means fewer out-of-memory crashes and the ability to run on more modest servers if needed. And because we reduced per-query CPU time so dramatically, a single server can handle many more concurrent queries, which translates to a more scalable service (or lower cloud bills to handle the same load). In short, engineering excellence translated directly into product excellence. We often say we’re “fanatical about performance” – this C++ story is exactly why. It’s not about winning benchmarks for bragging rights; it’s about enabling experiences and business opportunities that weren’t possible before.
Perhaps the most satisfying outcome of all this was hearing from new enterprise customers who evaluated our search platform and chose it because it was both powerful and fast. In an era where many assume you must trade off ease (Python) for speed (C++), we showed that with thoughtful design you can have the best of both: a developer-friendly interface powered by a beast under the hood. As a result, we signed on enterprise clients whose data scales dwarfed what our early Python-based system could handle – each new client’s dataset size now sometimes exceeds that of our first 50 customers combined, as highlighted in Matej’s talk. That is a tangible testament to the impact of this migration. When your technology can scale 1000×, it opens doorsgineering Excellence and the Immortal Language
Engineering Excellence and the Immortal Language
Rewriting Omnisearch’s engine in C++ was one of those rare decisions that proved overwhelmingly right. It wasn’t easy – it required careful thought, new hires with systems expertise, and plenty of debugging – but it paid off in performance, scalability, and even new capabilities (like advanced semantic search) that we could layer on once the foundations were solid. The journey from a Python prototype to a C++-powered workhorse taught us a lot about the tools we choose. Python was (and still is) fantastic for quickly standing up a product and iterating on features. But when it comes to squeezing out maximum performance and fine-tuning memory usage, nothing beats C++ for a job like ours. It truly is an “immortal language” in the sense that decades on, it remains the go-to for systems that demand every ounce of efficiency.
In the end, this isn’t a story about one language versus another as much as it is about using the right tool for the right job. We still use Python where it makes sense – for scripting, prototyping, and high-level integration – but we let C++ shine at what it does best. By respecting the strengths and weaknesses of each, we engineered a system that delivers an outstanding experience. And we had a lot of fun doing it: there’s a certain joy in diving into assembly listings or bit-level encodings to solve real problems, a joy you could sense in Marin Smiljanić’s and Matej Ferenčević’s retelling of this adventure (sprinkled with a bit of wit, of course).
To any tech leaders and engineers reading this: if you’re pushing the performance envelope, don’t be afraid to mix in some C++ – it might just give your product a new lease on life. Our journey proves that sometimes, to build something truly fast and scalable, you have to go low-level. In our case, embracing C++ meant the difference between a decent search tool and a great one. And that is why C++ still matters, deeply, in 2025.




